
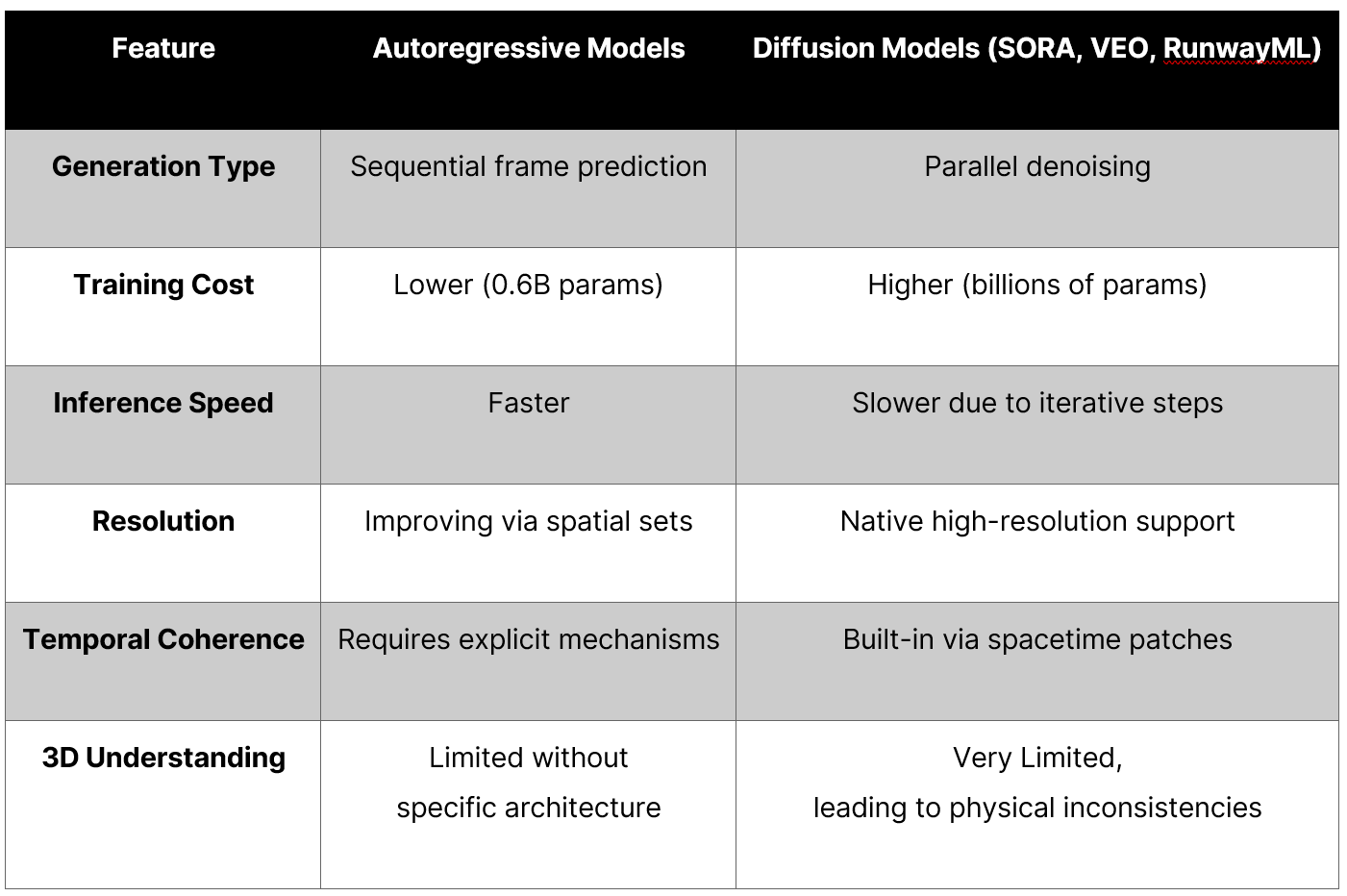
The technical shift extends to motion
If you’ve been following my writing recently, you’ll have noticed a piece about the flood of consistent character images coming through using the new image generator GPT-4o, and the technical shift happening beneath the surface to make these images happen so easily.
What if we extrapolate this same technological shift across motion and video too?
Beyond diffusion - the autoregressive advantage
Almost all video AI generators use some level of diffusion models to power their services - that’s OpenAI’s Sora, KlingAI, RunwayML, Google Veo 2, and Pika. I’ve been closely tracking how these diffusion models augment to allow us to obtain plausible physics and character consistencies for years, but this is where things are about to change.
So are multimodal LoRAs dead?
What is this new model architecture then?
Think of diffusion model videos like sculpting each frame from a block of marble - each frame requires the artist to chip away at noise until the desired image emerges. When they need the next frame, they’re essentially starting with a new block that needs to be carved again, struggling to maintain consistency with what came before.
Autoregressive models, however, work more like clay animation. They build each frame sequentially based on what already exists, with each new position informed by what came before it. This fundamental difference is why AR models maintain character consistency and temporal coherence by design, creating a naturally flowing narrative rather than a series of disconnected images forced to ‘play’ together.

What’s going on under the hood?
Rather than generating the entire video in one go through denoising (diffusion), AR models work sequentially - predicting each pixel and frame based on the VISUAL context of the previous content, much like how large language models predict each word based on previous words. So this means that like the images can keep style, character, objects, and text more accurately - this architecture enables video frames to better connect and control the next frame’s actions.
The opportunities here
- Resource and training efficiencies: AR models require fewer parameters (0.6B vs billions) compared to diffusion models, enabling faster inference and much lower training (and operating) costs - this opens the door for BETTER local branded multimodal LoRA controls! (she’s back baby!)
- More flexible generation length: They support variable-length video generation and in-context learning (imagine extending your videos indefinitely!). Also, by controlling the consistency and the IP adaptors (as we do now) we can add in branded filmic controls more easily.
- Consistency by design: The sequential generation will maintain characters, context, colour, movement, and scene consistency across multiple frames.
- More interdependent use cases: This simplifies the potential pipeline across multi-specialism production processes. Especially across real-time, experiential, and virtual / digital twinned environments. Imagine treating images, pencil drawings, 3D geometry, and videos as interchangeable functions! What a world!
Why does this need to change? The limitations of current diffusion models
There’s currently no broad consensus about which architecture is best for video generation. Today’s mainstream video models are primarily diffusion-based, essentially generating frames and trying (sub-training) to create temporal consistency between each frame. However, this approach comes with significant limitations:
- Lack of 3D understanding: Diffusion models have no intrinsic understanding of 3D space, or how physical objects should interact together in real or physics-restrained ways, which explains the warping and morphing artifacts we see a lot.
- Physical inconsistency: It’s not uncommon to see a person walking down a street in the first half of a clip and then “melting” into the ground in the second - the model has no concept of “hard” surfaces.
- Perspective limitations: Generating the same scene from different angles is extremely difficult due to the lack of spatial reasoning.

I’ve seen how these limitations influence using video AI in commercial production consistently. Autoregressive models will offer better temporal coherence by design, cheaper tokenisation (per effective generation), and faster creations - but it’s not a golden goose though.
The breakthrough in autoregressive video generation
I’ve been particularly impressed by NOVA (NOn-Quantized Video Autoregressive Model), which is autoregressive modelling for video generation.
One of the biggest hurdles with video AI is the scarcity of reliable quality training data for all of these video generation models. Unlike image models that use labelled datasets, video data is much harder to categorise:
- While the internet and branded asset libraries contain enormous amounts of video, this content often lacks proper labels, tags, or viable validation (beyond user ranking).
- The distribution of this content is heavily biased and skewed (the input data is a world of cat videos and influencer content).
- The “holy grail” is controllable, categorised, and consistent training data from a studio or production company, covered with multiple angles, lighting, and contexts.
In my work with agencies and production studios, I’ve seen how these data limitations affect all video AI generation approaches, but the sequential nature of AR models might provide advantages in learning from limited datasets.
We’re not there yet, and the middle ground solution will be a hybrid approach, but this is the promising direction for the future.
Key challenges to tackle in integrating a video AI pipeline
Temporal coherence
Maintaining consistency across multiple frames is the main control we’re looking for here. One of the biggest issues I see with video AI integration is the “temporal coherence” problem. How do we get characters, objects, products, colours, lighting, and backgrounds to stay consistent between multiple frames without morphing motion, hallucination rubbish, or warping anatomy? Hybrid models like ART-V are fixing this by integrating diffusion models for frame denoising and using AR for long-term narrative and body structure.

Resolution limitations
Traditional AR models struggle with higher fidelities and commercial resolutions. NOVA uses spatial set-by-set prediction, which processes image patches in parallel across frames to improve these resolutions and details without using multiple tools, upscalers, or stages.
What this means for production and creative workflows
All brands and agencies are looking for is the ability to trust in the outputs. That’s true of a hire, an innovation, a service line, or anything in your tech stack.
Can it do what it says it can do. And can it do it consistently?
So, what are we looking for with AR and diffusion models in the near future:
- Faster iterations: Quicker generation cycles for content creation. Are we going to get to “stock content” speeds, seeding results and options as fast as a meta-tagged search function?
- Extended narratives: We may soon see the end to hoping for 5 seconds of usable video with warping either side. With more consistency delivered across multiple shooting angles - shoot the scene: wide shot, mid shot, close up.
- Character consistency: Maintaining character and object appearance across longer sequences may become easier and more dependable.
- Lower resource requirements: More studios and brands can access this technology without enterprise-level compute capacity.
- Cost efficiencies at scale: As I’ve seen in other AI content creation areas, economies of scale will reduce per-video costs (PVC) significantly as volume increases and failures (hallucinations) decrease.
The future is probably hybrid and specialised
In my experience, the most exciting development I’m seeing isn’t AR vs diffusion - it’s how they’re being combined.
Models using AR for long-term structure and diffusion for per-frame refinement and resolution controls, creating coherent long-form videos with exceptional quality, and mixing these pipelines with effective vector DBs, fine-tuning, and key stage function controllers.
This hybridisation points to a future where we don’t choose between approaches but rather use the unique strengths of each for better results.

What’s next for production studios embracing AI content generation?
For the production teams who are already experimenting with AI, this evolution needs to start now, but in a future-proofed way - consider these start points:
- Pipeline integration: AR models’ efficiency makes them ideal for initial concepting, scoping, and storyboarding.
- Asset creation and evolution: Consider how consistent character generation could streamline pre-vis and creative asset development and animation, 2D and 3D world developments.
- Production integration: Variable-length generation opens new possibilities for flexible content creation.
- Mixed-reality implementations: As I’ve explored in my work, autoregressive with VP is a very interesting concept - the potential integration with these technologies could create innovative “mixed media” truly real-time marketing solutions.
Final thoughts
As someone who’s been passionate about modernising content creation and delivery throughout my career, I’m particularly excited about how AI is changing the landscape of video and content in general.
This same technical shift that’s made GPT-4o’s consistent character generation possible is now extending into the realm of motion.
For the creative studios and production companies I work with, this represents not just an incremental improvement in AI tools, but a fundamental shift in how visual AI frameworks can be conceived, developed, and integrated properly.


